下面就是小编带给大家的常用的网络数据爬取方法方法操作,希望能够给你们带来一定的帮助,谢谢大家的观看。
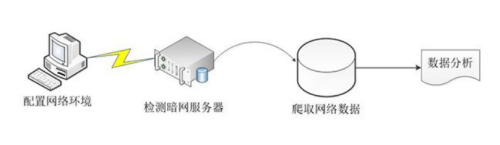
方法/步骤
我们知道,http协议共有8种方法,真正的浏览器至少支持两种请求够始网页的敏脂方法:GET和POST。
相对于urllib2而言,urllib模块只接受字符串参数,不能指定请求数据的方法,更无法设置请求报头。因此,urllib2被视为爬取数据所用“浏览器”的首选。
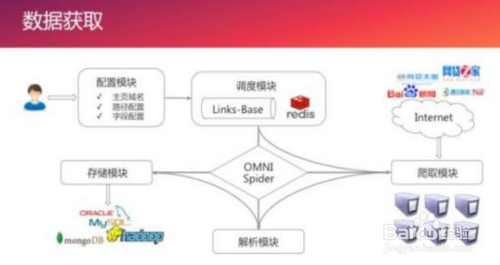
urllib2.urlopen除了可以接受字符串参数,还可以接受urllib2.Request对象。这意味着,我们可以灵活地设置请求的报头(header)。
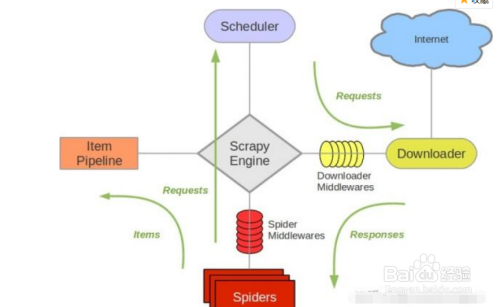
Beautiful Soup做为python的第三方库,可以帮助我们从网页源码中找到我们需要的数据。Beautiful Soup可以从一个HTML或者XML提取数据,它包含了简单的处理、遍历、搜索文档树、修改网页元素等功能。安装非常简单(如果没有解析器,也一并安装): pip install beautifulsoup4。
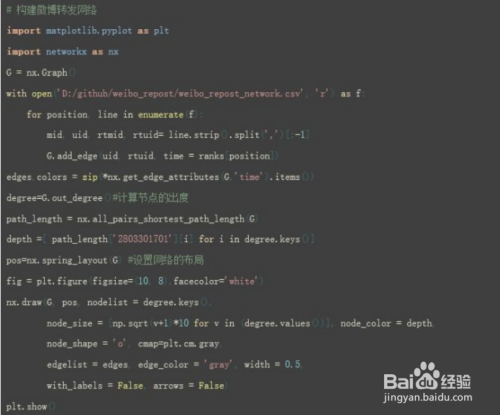
使用正则表达式解析数据 有时候,目标数据隐身于大段的文本中,无法透过html标签直接获取;或者,相同的标签数量众多,而目标数据只占其中的一小部分。
此时一般要借助于正则表达式了。下面的袭救各代码可以直接把年月日提取出来(提示:处理中文时,html源码和匹配模式必须使用utf-8编码,否则运行出错) 。
注意事项
以上就是小编带给大家的如何操作的关键所在,如果觉得本经验对你们有帮助,请给小编我进行一点小小的支持。大家也可以下面发表一下自己的看法。
个人意见,仅供参考。
经验内容仅供参考,如果您需解决具体问题(尤其法律、医学等领域),建议您详细咨询相关领域专业人士。
关键词: 爬走网络
上一篇:怎么在中国集邮总公司CPI商城买邮票?网上订购的方法是什么?
下一篇:最后一页
凡本网注明“XXX(非中国微山网)提供”的作品,均转载自其它媒体,转载目的在于传递更多信息,并不代表本网赞同其观点和其真实性负责。
常用的网络数据爬取方法,下面就是小编带给大家的常用的网络数据爬取方法方法操作,希望能够给你们带来一定
2023-04-24 23:06
怎么在中国集邮总公司CPI商城买邮票,每到邮票发行日,邮局门口总是排满了人,而对于比较偏远的地方,更是需
2023-04-24 23:09
幻塔奇异矿石在哪,在幻塔中,玩家可以在克罗恩矿区桥梁左侧建筑物内,可以找到奇异矿石。以下是详细的操作
2023-04-24 23:01
星辉娱乐发布异动公告,公司通过第三方软件推进实施AI技术的应用,处于AI技术的应用端,暂时并不直接拥有相
2023-04-24 22:35
科大讯飞(002230)在互动平台表示,科大讯飞(002230)在机器视觉拥有国际领先的成果,例如在计算机视觉顶级会
2023-04-24 22:34
三孚新科(688359)4月24日晚间公告,公司拟以不超过1亿元购买江西博泉化学有限公司(以下简称“江西博泉”)40
2023-04-24 21:31
海天瑞声(688787)公告,一季度净亏损1361万元,报告期内,公司毛利率受毛利水平较高的境外业务、以及标准化
2023-04-24 21:28
指南针(300803)4月24日晚间披露年报,2022年实现营业收入12 55亿元,同比增长34 6%;净利润3 38亿元,同比
2023-04-24 21:32
美股三大指数小幅低开,道指跌0 04%,纳指跌0 16%,标普500(161125)指数跌0 04%
2023-04-24 21:33
海报新闻记者汪雪然济南报道4月24日,山东省人民政府新闻办公室举行“数说山东看发展”系列新闻发布会,介
2023-04-24 20:50